
Delete Duplicate Rows from SQL Database Without a Primary Key
Just wanted to share with you a simple trick for deleting a duplicate row in your SQL table when you haven’t assigned a primary key. So you may be wondering how could this happen… Well, in most cases, it would happen when you are setting an Id to your item by hand instead of using Identity to automatically set the Id.
This leads us to another question, which is why would we set the Id by hand? Now here comes several answers, the best is the case where we need to insert a new item to the table and get its Id to be used in another table (like a foreign key for example);
if you’re familiar with MySQL, the first thing that comes to mind is “that’s why we’ve got the Scope_Identity”, but that’s with MySQL not MS-SQL. It’s true that Ms-SQL has similar functions, yet each has its disadvantage, so the only thing left (in several cases) is to set a unique Id manually.
 When setting Id manually, it may happen that we start filling the table with duplicate data (eg. accidently) before setting a primary key and applying its duplicate constraint. When an entry is duplicated exactly without having anything to differentiate it from other entries we get the following error:
When setting Id manually, it may happen that we start filling the table with duplicate data (eg. accidently) before setting a primary key and applying its duplicate constraint. When an entry is duplicated exactly without having anything to differentiate it from other entries we get the following error:
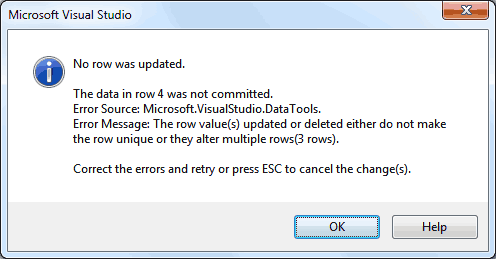
When setting Id manually, it may happen that we start filling the table with duplicate data (eg. accidently) before setting a primary key and applying its duplicate constraint. When an entry is duplicated exactly without having anything to differentiate it from other entries we get the following error:
The row value(s) updated or deleted either do not make the row unique or they alter multiple rows.
Of course, there are several solutions to this problem like creating a new fieldname to differentiate between the duplicate rows and delete one of them, or creating a new table to move the non-duplicated data to. However, if you’re looking for a neat simple trick that only aims to delete the duplicate entry, you may want to simply execute the following query:
SET ROWCOUNT 1 DELETE FROM mytable WHERE mycolumn = ‘columnname‘ That’s it! It only takes 3 lines to solve.


Mostafa Dafer
Computer & Communication Eng. Stdnt.
Founder & CEO of CoolesTech
Knows Arabic; English, learning French, Chinese, and Japanese
About me: steve.coolestech.com